Sedona 示例
Sedona 尝鲜
背景
Sedona 是一个正在Apache孵化中的用于处理海量空间数据项目,在加入Apache前,Sedona名为Geospark。
Sedona可以利用Maven,SBT构建Java,Scala 项目,同时提供了Python及R语言API。
Sedona架构如下:

示例程序
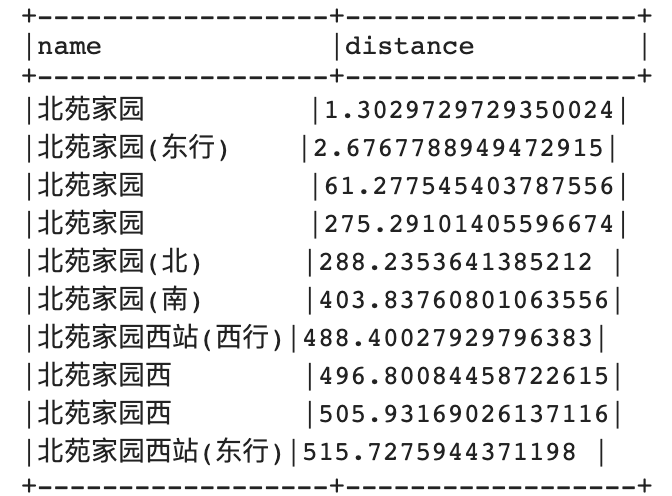
利用Sedona搜索距离最近的十个公交站。
主要pom.xml配置如下:
<properties>
<spark.version>3.0.0</spark.version>
<gt-geometry.version> 20.1 </gt-geometry.version>
<scala.tools.version>2.13</scala.tools.version>
<scala.version>2.12.10</scala.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
<exclusions>
<exclusion>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.locationtech.jts</groupId>
<artifactId>jts-core</artifactId>
<version>1.16.0</version>
</dependency>
<dependency>
<groupId>org.geotools</groupId>
<artifactId>gt-geometry</artifactId>
<version>${gt-geometry.version}</version>
</dependency>
<dependency>
<groupId>org.geotools</groupId>
<artifactId>gt-epsg-hsql</artifactId>
<version>${gt-geometry.version}</version>
</dependency>
<dependency>
<groupId>org.geotools</groupId>
<artifactId>gt-referencing</artifactId>
<version>${gt-geometry.version}</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.4</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.scalatest</groupId>
<artifactId>scalatest_${scala.tools.version}</artifactId>
<version>3.2.9</version>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.sedona</groupId>
<artifactId>sedona-python-adapter-3.0_2.12</artifactId>
<version>1.0.1-incubating</version>
</dependency>
<dependency>
<groupId>org.apache.sedona</groupId>
<artifactId>sedona-viz-3.0_2.12</artifactId>
<version>1.0.1-incubating</version>
</dependency>
</dependencies>
主要代码如下:
import org.apache.sedona.core.serde.SedonaKryoRegistrator
import org.apache.sedona.core.spatialOperator.KNNQuery
import org.apache.spark.serializer.KryoSerializer
import org.apache.spark.sql.SparkSession
import org.apache.sedona.sql.utils.{Adapter, SedonaSQLRegistrator}
import org.apache.spark.sql.types.StringType
import org.apache.spark.sql.functions.{col, udf}
/**
* @time 9/15/21 5:25 PM
* @author ce39906
* @email ce39906@163.com
*/
object GeoSparkDemo {
def main(args: Array[String]): Unit = {
val sparkSession = SparkSession.builder()
.enableHiveSupport()
.config("spark.serializer", classOf[KryoSerializer].getName) // org.apache.spark.serializer.KryoSerializer
.config("spark.kryo.registrator", classOf[SedonaKryoRegistrator].getName)
.getOrCreate()
import sparkSession.implicits._
sparkSession.sql("set hive.exec.dynamic.partition=true")
sparkSession.sql("set hive.exec.dynamic.partition.mode=nonstrick")
SedonaSQLRegistrator.registerAll(sparkSession)
val table = "test_database.test_table"
val sql =
"""select city_id, name, location from
|%s where dt = '20210630'
""".stripMargin.format(table)
var platformDf = sparkSession.sql(sql)
def locationValid(location: String) : Int = {
val latlon = location.split(",")
if (latlon.length != 2) {
return 0
}
val lat = latlon(0).toDouble
val lon = latlon(1).toDouble
val res = lon > -180.0 && lon < 180.0 && lat > -90.0 && lat < 90.0
if (res) 1 else 0
}
val UDFLocationValid = udf(locationValid _)
platformDf = platformDf.withColumn("valid", UDFLocationValid(col("location")))
.where("valid == 1")
def createWktPoint(latlon: String) : String = {
val latlonArr = latlon.split(",")
val lat = latlonArr(0)
val lon = latlonArr(1)
val lonlat = lon + "," + lat
GeoUtils.createWKTPoint(latlon)
}
val UDFCreateWktPoint = udf(createWktPoint _)
val df = platformDf.withColumn("wkt_point", UDFCreateWktPoint(col("location")))
df.createOrReplaceTempView("rawdf")
val spatialDf = sparkSession.sql(
"""select ST_Transform(ST_GeomFromWKT(wkt_point), "epsg:4326", "epsg:3857") as platform_location,
| name, city_id from rawdf
""".stripMargin
)
spatialDf.createOrReplaceTempView("spatialdf")
val targetPlatform = "POINT (40.04004494170224 116.42194976190544)"
val knnSql =
"""select name,
|ST_Distance(ST_Transform(ST_GeomFromWKT("%s"), "epsg:4326", "epsg:3857"), platform_location) as distance
|from spatialdf
|order by distance
|limit 10
""".stripMargin.format(targetPlatform)
val knnDf = sparkSession.sql(knnSql)
knnDf.show(10, truncate = false)
}
}
需要注意的是,Sedona计算点间距离是基于平面坐标系的,如果是GCJ02坐标的话需要首先转为WGS84坐标,然后将WGS84坐标转为平面坐标,关于坐标系介绍见epsg
上述代码段中ST_GeomFromWKT("%s"), "epsg:4326", "epsg:3857")的作用就是将WGS84坐标转为平面坐标。
⚠️ Sedona在处理经纬度坐标的格式是先纬度后经度
执行结果如下:
参考资料
https://sedona.apache.org/
https://epsg.io/