Boost Spirit
我见过的最难懂的boost 库
What is boost spirit
boost spirit is an object-oriented,recursive-descent parser and output generation library for C++.It allows you to write grammars and format descripting using a format similar to Extended Backs Naur Form(EBNF) directly in C++.
The figure below shows the overall structure of Boost Spirit library.
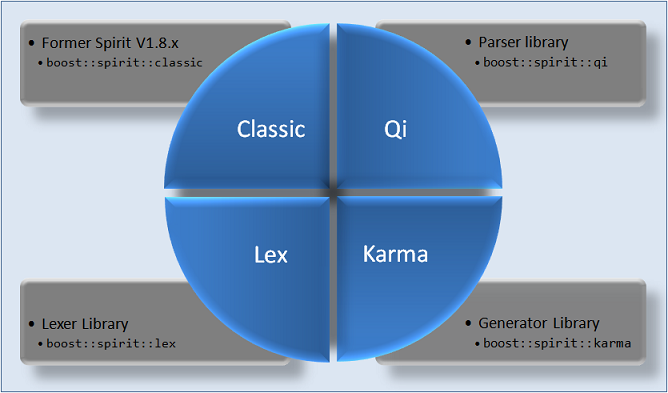
The three components Qi,Kama and Lex are designed to be used either stand alone or together. The general methodology is to use the token sequence generated by Lex as the input for a parser generated by Qi. On the opposite side of the equation,the hierarchical data structures generated by Qi are used for the output generators created using Kama.
The place of Spirit.Qi and Spirit.Kama in a data transformation flow of a typical application.
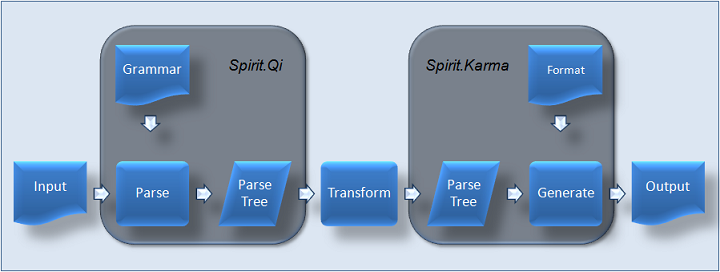
Qi- Writing Parsers
Spirit.Qi is designed to be a practical parsing tool. Scanf ,boost::regex or boost::tokenizer do not scale well when we need to write more elaborate parsers.
Examples
Example #1 parsing a number
Create a parser that will parse a floating-point number.
double_
Example #2 parsing 2 numbers
Create a parser that will accept a line consisting of 2 floating-point numbers.
double_ >> double_
Example #3 parsing zero or more numbers
Create a parser that will accept zero or more floating-point numbers.
*double_
Example #4 parsing a comma-delimited list of numbers
This example will create a parser that accepts a comma-delimited list of numbers.
double_ >> *(char_(',') >> double_)
Notice char_(',') is a literal charcter parser that can recognize the comma ','.
Let's Parse
We are done with defining the parser.So the next step is invoking this parser to do its work.Here we will use phrase_parse function. One overload of this function accepts four arguments.
- iterator pointing to the start of the input.
- iterator pointing to the end of the input.
- parser object
- another parser called the skip parser
template<typename Iterator>
bool parse_numbers(Iterator first, Iterator last)
{
using qi::double_;
using qi::phrase_parse;
using ascii::space;
bool r = pharse_parse(
first,
last,
double_ >> *(',' >> double_),
space
);
if (fisrt != last)
return false;
return r;
}
Parser Semantic Actions
The previous example was very simple.It only recognized data,but did noting with it.Now we want to extract information from what was parsed.
Semantic actions may be attached to any point in the grammar specification. These functions are C++ functions or function objects that are called whenever a part of the parser successfully recognizes a portion of the input.
Example of Semantic Actions
- using plain function pointer
- using simple function object
- using boost.bind with a plain function
- using boost.bind with a member function
- using boost.lambda
Such as:
namespace client
{
namespace qi = boost::qi;
// A plain function
void print(const int& i)
{
std::cout << i << std::endl;
}
// A member function
struct writer
{
void print(const int& i) const
{
std::cout << i << std::endl;
}
};
// A function object
struct print_action
{
void operator()(const int& i,qi::unset_type,qi::unset_type) const
{
std::cout << i << std::endl;
}
};
}
All examples parse inputs of the form:
"{integer}"
These below shows the usages
using boost::spirit::qi::int_;
using boost::spirit::qi::parse;
using client::print;
using client::writer;
using clinet::print_action;
const char* fisrt = "{43}";
const char* last = first + std::strlen(first);
// example using plain function
parse(first,last,'{'>>int_[&print]>>'}');
// example using simple function object
parse(first,last,'{'>>int_[print_action()]>>'}');
// example using boost bind with a plain function
parse(fisrt,last,'{' >> int_[boost::bind(&print,_1)]>>'}');
// example using boost bind with a member function
parse(first,last,'{'>> int_[boost::bind(&writer::print,&w,_1)]>>'}');
// example using boost lambda
namespace lambda = boost::lambda;
using lambda::_1;
parse(first,last,'{' >> int_[std::cout << _1 << '\n'] >> '}');
Phoenix
Phoenix , a companion library bundled with Spirit. is sepcifically suited for binding semantic actions. It is like Boost.lambad on sterodis, with spiecial custom featrues that make it easy to inergrate semantic action with Spirit.
Complex - Our first complex parser
A parser that parses complex numbers.This time we are using Phoenix to do the semantic actions.
Here is a simple parser expression for complex numbers.
'(' >> double_ >> -(',' >> double_) >> ')'
| double_
This parser can parse complex numbers of the form:
(123.22,2121.21)
(213.33)
212.33
This below shows example of action with phoniex
namespace client
{
template<typename Iterator>
bool parse_complex(Iterator first,Iterator last,std::complex<double>& c)
{
using boost::spirit::qi::double_;
using boost::spirit::qi::_1;
using boost::spirit::qi::phrase_parse;
using boost::spirit::ascii::space;
using boost::phoenix::ref;
double rN = 0.0;
double iN = 0.0;
bool r = phrase_parse(
first,
last,
(
'(' >> double_[ref(rN) = _1]
>> -(',' >> double_[ref(iN) = _1]) >> ')'
| double_[ref(rN) = _1]
),
space
);
if (!r || first != last)
return false;
c = std::complex<double>(rN,iN);
return r;
}
}
Sum - adding numbers
Here is a parser that sums a comma-separated list of numbers.
namespace qi = boost::spirit::qi;
namespace ascii = boost::spirit::ascii;
namespace phoenix = boost::spirit::phoenix;
using qi::double_;
using qi::_1;
using ascii::space;
using phoenix::ref;
template<typename Iterator>
bool adder(Iterator first,Iterator last,double& n)
{
bool r = qi::phrase_parse(
first,
last,
(
double_[ref(n) = _1] >> *(',' >> double_[ref(n) += _1])
),
space
);
if (fisrt != last)
return false;
return r;
}
Number List - stuffing numbers into a std::vector
This sample demonstrates a parser for a comma separated list of numbers. The numbers are inserted in a vector using phoenix.
template <typename Iterator>
bool parse_numbers(Iterator fisrt,Iterator last,std::vector<double>& v)
{
using qi::double_;
using qi::phrase_parse;
using qi::_1;
using ascii::space;
using phoenix::push_back;
using phoenix::ref;
bool r = phrase_parse(
first,
last,
(
double_[push_back(ref(v),_1)] >>
*(',' >> double_[push_back(ref(v),_1)])
),
space
);
if(first != last)
return false;
return r;
}
Number List Redux - list syntax
So far, we've been using the syntax:
double_ >> *(',' >> double_)
to parse a comma-delimited list of numbers.Such lists are common in parsing and Spirit provides a simpler shortcut for them
double_ % ','
reads as a list of doubles separted by ','.
The last example could be done as this:
template<typename Iterator>
bool parse_numbers(Iterator first,Iterator last,std::vector<double>& v)
{
using qi::double_;
using qi::phrase_parse;
using qi::_1;
using ascii::space;
using phoenix::push_back;
using phoenix::ref;
bool r = phrase_parse(
first,
last,
(
double_[ref(v),_1] % ','
),
space
);
if (first != last)
return false;
return r;
}
Number List Attribute - one more,with style
As we know,the double_ parser has a doubel attribute. All parsers have an attribute,even complex parsers.
Our parser
doubel_ % ','
has an attribute of std::vector
So we can simply pass in a std::vector
- iterator pointing to start of the input
- iterator pointing to last of the input
- the parser object
- another parser called skip parser
- the parse's attribute
bool r = phrase_parse(
first,
last,
(
double_ % ','
),
space,
v
);
Roman Numerals
This example demonstrates:
- symbol table
- rule
- grammar
Symbol table
Each entry in a symbol table has an associated mutable data solt. In this regard, one can view the symbol table as an associative container of key-value pairs where the keys are strings.
Here is a parser for roman hundreds(100..900) using the symbol table. Keep in mind that the data associated with each slot is the parser's attribute(which is passed to attached semantic actions).
struct hundreds_ : qi::symbols<char, unsigned>
{
hundreds_()
{
add
("C",100)
("CC",200)
("CCC",300)
("CD",400)
("D", 500)
("DC", 600)
("DCC",700)
("DCCC",800)
("CM",900);
}
} hundreds;
we also can define tens ones symbol table.They are all parsers.
Rules
Up until now,we have been inlining our parser expressions, passing them directly to the phrase_parse function. The expression evalutes into a temporary,unnamed parser which is passed into the phrase_parse function, used and then destroyed. This is fine for small parsers. When the expressions get complicated, you'd want to break the expressions into smaller easier-to-understand pieces, name them, and refer to them from other expressions by name.
A parser expression can be assigned to what is called a "rule".Threr are various ways to declare rules.The simplest form is :
rule<Iterator> r;
// this rule cannot used by phrase_parse function,
// it can only be used by parse function -- a version that does not do white space skipping.
// If you want to have it skip white spaces,you need to pass in the type skip parser.
rule<Iterator,Skipper> r;
rule<string::iterator,space_type> r;
// This type of rule can be used for both
// phrase_parse and parse.
There is one more rule form you should know about.
rule<Iterator,Signature,Skipper> r;
The Signature specifies athe attributes of the rule. Recall that the double_ parser has an attribute of double. To be precise, these are synthesized attributes.The parser "synthesized" the attribute value.Think of them as the function return value.
There is another type of attribute called "inherited" attribute. You can think them as function arguments. And,rightly so, the rule signature is a function signature .
After having declared a rule,you can now assign any parser expression to it. Example:
r = double_ >> *(',' >> double_);
Grammars
A grammar encapsulates one or more rules.It has the same template parameters as the rule.You can declare a grammar by:
- deriving a struct from the grammar class template
- declare one or more rules as member variables
- initialize the base grammar class by giving it the start rule(its the first rule that gets called when the grammar starts parsing)
- initalize your rules in your constrctor.
The rommon numeral grammar is a very nice and simple example of a grammar.
template<typename Iterator>
struct roman :qi::grammar<Iterator,unsigned()>
{
roman() : roman::base_type(start)
{
using qi::eps;
using qi::lit;
using qi::_val;
using qi::_1;
using ascii::char_;
start = eps [_val = 0] >>
(
+lit('M') [_val += 1000]
|| hundreds [_val += _1]
|| tens [_val += _1]
|| ones [_val += _1]
)
}
qi::rule<Iterator,unsigned()> start;
}
- the grammar and start rule sinature is unsigned() it has a synthesized attribute(return value) of type unsigned whith on inherited attributeds(argumnents).
- roman::base_type is a typedef for grammar<Iterator,unsigned()>
- _val is another Phoenix placeholder representing the rule's synthesized attribute
- eps is a special spirit parser that consumes no input but is always successful. We use it to initialize _val,the rule's synthesized attribute, to zero before anything else. Using eps this way is good for doing pre and post initializations.
- the example a || b reads, match a or b and in sequence.That is if both a and b match, it must be in sequence; this is equivalen to a >> -b | b,but more efficient.
Usage
bool r = parse(iter,end,roman_parser,result);
if (r && iter == end)
{
std::cout << "Parse success.\n";
std::cout << "Result = " << result << std::endl;
}
Employee - Pasing into structs
This section shows how to parse and place the reult into a C++ struct.
fisrtly, let's create a struct representing an employee.
struct employee
{
int age;
std::string surname;
std::string forename;
double salary;
};
now we will write a parser for our employee. Inputs will be of the form.
employee{ age,"surname","forename",salary }
template<typename Iterator>
struct employee_parser : qi::grammar<Iterator,employee(),ascii::space_type>
{
employee_parser():employee_parser::base_type(start)
{
using qi::int_;
using qi::lit;
using qi::double_;
using qi::lexeme;
using ascii::char_;
quoted_string %= lexeme['"' >> +(char_ - '"') >> '"'];
start %=
lit("employee")
>> '{'
>> int_ >> ','
>> quoted_string >> ','
>> quoted_string >> ','
>> double_
>> '}'
;
}
qi::rule<Iterator,std::string(),ascii::space_type> quoted_string;
qi::rule<Iterator,employee(),ascii::space_type> start;
};
Lexeme
lexeme['"' >>(char_ - '"') >> '"']
lexeme inhibits sapce skipping from the open brace to the closing space.The expression parses quoted strings.
+(char_ - '"')
parses one or more chars,except the double quote. It stops when it sees a double quote.
+a matches one or more,its attribute is a std::vector where A is the attribute of a .
Sequence Attribute
now what's the attribute of
'"' >> (char_ - '"') >>'"'
a >> b >> c
fusion::vector<A,B,C>
// is a tuple
Some parser,especially those very little parsers like '"' do not have attributes.
Nodes without attributes are disregarded.
so, '"' >> (char_ - '"') >>'"' 's attribue is
fusion::vector<std::vector<char>>
but there is one more collpase rule.if the attribute is followed by a single element fusion::vector, The element is stripped naked from its container. so the attribute come to this
std::vector<char>
Auto Rules
it is typical to see rules like
r = p[_val = _1]
if you have a rule definiton such as the above,where the attribute of the right hand side of the rule is compitable with the left hand side.then you can rewrite is as:
r %= p;
so
quoted_string %= lexeme['"' >> +( char_ -'"') >> '"'];
is simple version of
quoted_string = lexeme['"' >> + (char_ - '"') >> '"'][_val = _1];
Note: r %= p and r = p are equivalent if there are no semantic actions associated with p.
In case you are wondering, lit("employee") is the same as "employee". We had to wrap it inside lit because immediately after it is >> '{'. You can't right-shift a char[] and a char - you know, C++ syntax rules.
Karma - Writing Generators
Spirit.Karma - what's that?
Spirit.Karma is the counterpart to spirit.qi.
Some people say it's the Yin to Spirit.Qi's Yang. Spirit.karma is generating byte sequences from internal data structures as Spirit.Qi is parsing byte sequences into those internal data structures.
Why should you use a generator library for such a simple thing as output generation? Programmers have been using printf, std::stream formatting, or boost::format for quite some time. The answer is - yes, for simple output formatting tasks those familiar tools might be a quick solution. But experience shows: as soon as the formatting requirements are becoming more complex output generation is getting more and more challenging in terms of readability, maintainability, and flexibility of the code. Last, but not least, it turns out that code using Spirit.Karma runs much faster than equivalent code using either of the 'straight' methods mentioned above.
In terms of development simplicity and ease in deployment, the same is true for Spirit.Karma as has been described elsewhere in this documentation for Spirit.Qi: the entire library consists of only header files, with no libraries to link against or build. Just put the spirit distribution in your include path, compile and run. Code size? Very tight, essentially comparable to hand written code.
Examples
Trivial Example Generating a number
double_
Generating two numbers
double_ << double_
Generating one or more numbers
*double_
Generating a comma-delimited list of numbers
double_ << *(lit(',')) << double_
Let's generate
template<typename OutputIterator>
bool generate_numbers(OutputIterator& sink,std::list<double> const& v)
{
using karma::double_;
using karma::generate_delimited;
using ascii::space;
bool r = genated_delimited(
sink,
double_ << *(',' << double_),
v
);
return r;
}